В связи с растущим объемом разрабатываемого ПО проблема безопасности становится все более актуальной. Одним из вариантов ее решения может стать применение безопасного цикла создания продуктов, включая планирование, проектирование, разработку, тестирование. Такой подход позволяет получать на выходе решение с продуманной системой безопасности, которое не потребуется затем многократно “латать" из-за существующих уязвимостей. В данной статье пойдет речь об одной из важных практик, применяемых на этапе тестирования, – статическом анализе кода.
Александр Миноженко
Старший исследователь департамента анализа кода
в ERPScan (дочерняя компания Digital Security)
При статическом анализе кода происходит анализ программы без ее реального исполнения, а при динамическом анализе – в процессе исполнения. В большинстве случаев под статическим анализом подразумевают анализ, осуществляемый с помощью автоматизированных инструментов исходного или исполняемого кода.
Исторически первые инструменты статического анализа (часто в их названии используется слово lint) применялись для нахождения простейших дефектов программы. Они использовали простой поиск по сигнатурам, то есть обнаруживали совпадения с имеющимися сигнатурами в базе проверок. Они применяются до сих пор и позволяют определять "подозрительные" конструкции в коде, которые могут вызвать падение программы при выполнении.
Недостатков у такого метода немало. Основным является то, что множество "подозрительных" конструкций в коде не всегда являются дефектами. В большинстве случаев такой код может быть синтаксически правильным и работать корректно. Соотношение "шума" к реальным дефектам может достигать 100:1 на больших проектах. Таким образом, разработчику приходится тратить много времени на его отсеивание от реальных дефектов, что отменяет плюсы автоматизированного поиска.
Несмотря на очевидные недостатки, такие простые утилиты для поиска уязвимостей до сих пор используются. Обычно они распространяются бесплатно, так как коммерческого применения они, по понятным причинам, не получили.
Второе поколение инструментов статического анализа в дополнение к простому поиску совпадений по шаблонам оснащено технологиями анализа, которые до этого применялись в компиляторах для оптимизации программ. Эти методы позволяли по анализу исходного кода составлять графы потока управления и потока данных, которые представляют собой модель выполнения программы и модель зависимостей одних переменных от других. Имея данные, графы можно моделировать, определяя, как будет выполняться программа (по какому пути и с какими данными).
Поскольку программа состоит из множества функций, процедур модулей, которые могут зависеть друг от друга, недостаточно анализировать каждый файл по отдельности. Для полноценного межпроцедурного анализа необходимы все файлы программы и зависимости.
Основным достоинством этого типа анализаторов является меньше количество "шума" за счет частичного моделирования выполнения программ и возможность обнаружения более сложных дефектов.
Процесс поиска уязвимостей в действии
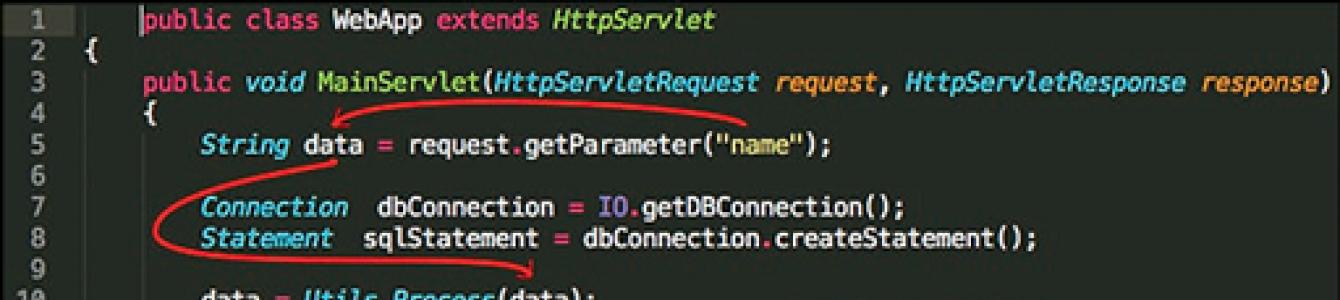
Для иллюстрации приведем процесс поиска уязвимостей инъекции кода и SQL-инъекции (рис. 1).

Для их обнаружения находятся места в программе, откуда поступают недоверенные данные (рис. 2), например, запрос протокола HTTP.

На листинге (рис. 1) 1 на строке 5 данные получаются из HTTP запроса, который поступает от пользователей при запросе Web-страницы. Например, при запросе страницы “http://example.com/main?name =‘ or 1=‘1”. Строка or 1=‘1 попадает в переменную data из объекта request, который содержит HTTP-запрос.
Дальше на строке 10 идет вызов функции Process с аргументом data, которая обрабатывает полученную строку. На строке 12 – конкатенация полученной строки data и запроса к базе данных, уже на строке 15 происходит вызов функции запроса к базе данных c результирующим запросом. В результате данных манипуляции получается запрос к базе данных вида: select * from users where name=‘’ or ‘1’=‘1’.
Что означает выбрать из таблицы всех пользователей, а не пользователя с определенным именем. Это не является стандартным функционалом и влечет нарушение конфиденциальности, что соответственно означает уязвимость. В результате потенциальный злоумышленник может получить информацию о всех пользователях, а не только о конкретном. Также он может получить данные из других таблиц, например содержащих пароли и другие критичные данные. А в некоторых случаях – исполнить свой вредоносный код.
Статические анализаторы работают похожим образом: помечают данные, которые поступают из недоверенного источника, отслеживаются все манипуляции с данными и пытаются определить, попадают ли данные в критичные функции. Под критичными функциями обычно подразумеваются функции, которые исполняют код, делают запросы к БД, обрабатывают XML-документы, осуществляют доступ к файлам и др., в которых изменение параметра функции может нанести ущерб конфиденциальности, целостности и доступности.
Также возможна обратная ситуация, когда из доверенного источника, например переменных окружения, критичных таблиц базы данных, критичных файлов, данные поступают в недоверенный источник, например генерируемую HTML-страницу. Это может означать потенциальную утечку критичной информации.
Одним из недостатков такого анализа является сложность определения на пути выполнения программ функций, которые осуществляют фильтрацию или валидацию значений. Поэтому большинство анализаторов включает набор стандартных системных функций фильтрации для языка и возможность задания таких функций самостоятельно.
Автоматизированный поиск уязвимостей
Достаточно сложно достоверно определить автоматизированными методами наличие закладок в ПО, поскольку необходимо понимать, какие функции выполняет определенный участок программы и являются ли они необходимыми программе, а не внедрены для обхода доступа к ресурсам системы. Но можно найти закладки по определенным признакам (рис. 3). Например, доступ к системе при помощи сравнения данных для авторизации или аутентификации с предопределенными значениями, а не использование стандартных механизмов авторизации или аутентификации. Найти данные признаки можно с помощью простого сигнатурного метода, но анализ потоков данных позволяет более точно определять предопределенные значения в программе, отслеживая, откуда поступило значение, динамически из базы данных или он было "зашито" в программе, что повышает точность анализа.

Нет общего мнения по поводу обязательного функционала третьего поколения инструментов статического анализа. Некоторые вендоры предлагают более тесную интеграцию в процесс разработки, использование SMT-решателей для точного определения пути выполнения программы в зависимости от данных.
Также есть тенденция добавления гибридного анализа, то есть совмещенных функций статического и динамического анализов. У данного подхода есть несомненные плюсы: например, можно проверять существование уязвимости, найденной с помощью статического анализа путем эксплуатации этой уязвимости. Недостатком такого подхода может быть следующая ситуация. В случае ошибочной корреляции места, где не было доказано уязвимостей с помощью динамического анализа, возможно появление ложноотрицательного результата. Другими словами, уязвимость есть, но анализатор ее не находит.
Если говорить о результатах анализа, то для оценки работы статического анализатора используется, как и в статистике, разделение результата анализа на положительный, отрицательный, ложноотрицатель-ный (дефект есть, но анализатор его не находит) и ложнопо-ложительный (дефекта нет, но анализатор его находит).
Для реализации эффективного процесса устранения дефектов важно отношение количества истинно найденных ко всем найденным дефектам. Данное отношение называют точностью. При небольшой точности получается большое соотношение истинных дефектов к ложноположительным, что так же, как и в ситуации с большим количеством шума, требует от разработчиков много времени на анализ результатов и фактически нивелирует плюсы автоматизированного анализа кода.
Для поиска уязвимостей особенно важно отношение найденных истинных уязвимостей ко всем найденным, поскольку данное отношение и принято считать полнотой. Ненайденные уязвимости опаснее ложнопо-ложительного результата, так как могут нести прямой ущерб бизнесу.
Достаточно сложно в одном решении сочетать хорошую полноту и точность анализа. Инструменты первого поколения, работающие по простому совпадению шаблонов, могут показывать хорошую полноту анализа, но при этом низкую точность из-за ограничения технологий. Благодаря тому что второе поколение анализаторов может определять зависимости и пути выполнения программы, обеспечивается более высокая точность анализа при такой же полноте.
Несмотря на то что развитие технологий происходит непрерывно, автоматизированные инструменты до сих пор не заменяют полностью ручной аудит кода. Такие категории дефектов, как логические, архитектурные уязвимости и проблемы с производительностью, могут быть обнаружены только экспертом. Однако инструменты работают быстрее, позволяют автоматизировать процесс и стоят дешевле, чем работа аудитора. При внедрении статического анализа кода можно использовать ручной аудит для первичной оценки, поскольку это позволяет обнаруживать серьезные проблемы с архитектурой. Автоматизированные же инструменты должны применяться для быстрого исправления дефектов. Например, при появлении новой версии ПО.
Существует множество решений для статического анализа исходного кода. Выбор продукта зависит от поставленных задач. Если необходимо повысить качество кода, то вполне можно использовать анализаторы первого поколения, использующие поиск по шаблонам. В случае когда нужно найти уязвимости в ходе реализации цикла безопасной разработки, логично использовать инструменты, использующие анализ потока данных. Ну а если опыт внедрения средств статического и динамического анализа уже имеется, можно попробовать средства, использующие гибридный анализ.
Колонка эксперта
Кибервойны: кибероружие
Петр
Ляпин
Начальник службы информационной безопасности, ООО “НИИ ТНН” (“Транснефть”)

Глядя на фактически развернутую гонку кибервооружений, прежде всего следует уяснить ряд фундаментальных положений в этой области.
Во-первых, война – международное явление, в котором участвуют два или более государства. Война подчиняется своим законам. Один из них гласит: "воюющие не пользуются неограниченным правом в выборе средств нанесения вреда неприятелю" 1 .
Во-вторых, давно канули в Лету те времена, когда вопросы войны и мира конфликтующие стороны могли решать самостоятельно. В условиях глобализации война становится делом всего международного сообщества. Более того, есть вполне действенный стабилизационный механизм – Совбез ООН. Однако в настоящий момент применять его к конфликтам в киберпространстве крайне затруднительно.
В-третьих, понятие кибервойны и кибероружия ни в одном действующем международном акте нет. Тем не менее следует разграничивать киберсредства, предназначенные для нанесения вреда (собственно кибероружие), и средства различного рода шпионажа. При этом термин "кибероружие" широко используется в том числе видными представителями научного сообщества.
Удачным видится определение кибероружия, данное профессором МГЮА В.А. Батырем: технические и программные средства поражения (устройства, программные коды), созданные государственными структурами, которые конструктивно предназначены для воздействия на программируемые системы, эксплуатацию уязвимостей в системах передачи и обработки информации или программно-технических системах с целью уничтожения людей, нейтрализации технических средств, либо разрушения объектов инфраструктуры противника 2 . Это определение во многом соответствует объективной действительности – не всякий "удачный вирус" есть кибероружие.
Так, к кибероружию можно отнести: Stuxnet и Flame, ботнеты, используемые для распределенных атак, массово внедряемые на этапе производства элементной базы аппаратные и программные закладки. Последнее, к слову, серьезнейшая проблема, масштаб которой невозможно переоценить. Достаточно взглянуть на перечень закладок АНБ США (от коммутаторов до USB-кабелей), опубликованный немецким СМИ Spiegel в декабре 2013 г. Смартфоны, ТВ, холодильники и прочая бытовая техника, подключенная к Интернету, вообще стирает всякие границы прогнозов.
___________________________________________
1 Дополнительный протокол I 1977 г. к Женевским конвенциям о защите жертв войны 1949 г.
2 Статья В.А. Батыря в Евразийском юридическом журнале (2014, №2) “Новые вызовы XXI в. в сфере развития средств вооруженной борьбы".
При написании кода на C и C++ люди допускают ошибки. Многие из этих ошибок находятся благодаря -Wall , ассертам, тестам, дотошному code review, предупреждениям со стороны IDE, сборкой проекта разными компиляторами под разные ОС, работающие на разном железе, и так далее. Но даже при использовании всех этих мер ошибки часто остаются незамеченными. Немного улучшить положение дел позволяет статический анализ кода. В этой заметке мы познакомимся с некоторыми инструментами для произведения этого самого статического анализа.
CppCheck
CppCheck является бесплатным кроссплатформенным статическим анализатором с открытым исходным кодом (GPLv3). Он доступен в пакетах многих *nix систем из коробки. Также CppCheck умеет интегрироваться со многими IDE. На момент написания этих строк CppCheck является живым, развивающимся проектом.
Пример использования:
cppcheck ./ src/
Пример вывода:
: (error) Common realloc mistake: "numarr" nulled but not
freed upon failure
: (error) Dangerous usage of "n" (strncpy doesn"t always
null-terminate it)
CppCheck хорош тем, что он довольно быстро работает. Нет повода не добавить его прогон в систему непрерывной интеграции , чтобы исправлять прямо все-все-все выводимые им предупреждения. Даже несмотря на то, что многие из них на практике оказываются ложно-положительными срабатываниями.
Clang Static Analyzer
Еще один бесплатный кроссплатформенный статический анализатор с открытыми исходным кодом. Является частью так называемого LLVM-стэка . В отличие от CppCheck работает существенно медленнее, но и ошибки находит куда более серьезные.
Пример построения отчета для PostgreSQL :
CC
=/
usr/
local/
bin/
clang38 CFLAGS
="-O0 -g"
\
./
configure --enable-cassert
--enable-debug
gmake
clean
mkdir
../
report-201604
/
/
usr/
local/
bin/
scan-build38 -o
../
report-201604
/
gmake
-j2
Пример построения отчета для ядра FreeBSD :
# использование своего MAKEOBJDIR позволяет собирать ядро не под рутом
mkdir
/
tmp/
freebsd-obj
# сама сборка
COMPILER_TYPE
=clang /
usr/
local/
bin/
scan-build38 -o
../
report-201604
/
\
make
buildkernel KERNCONF
=GENERIC MAKEOBJDIRPREFIX
=/
tmp/
freebsd-obj
Идея, как несложно догадаться, заключается в том, чтобы сделать clean, а затем запустить сборку под scan-build.
На выходе получается очень симпатичный HTML-отчет с подробнейшими пояснениями, возможностью фильтровать ошибки по их типу, и так далее. Обязательно посмотрите на офсайте как это примерно выглядит.
В данном контексте не могу не отметить, что в мире Clang/LLVM есть еще и средства динамического анализа, так называемые «санитайзеры». Их много, они находят очень крутые ошибки и работают быстрее, чем Valgrind (правда, только под Linux). К сожалению, обсуждение санитайзеров выходит за рамки настоящей заметки, поэтому ознакомьтесь с ними самостоятельно .
PVS-Studio
Закрытый статический анализатор, распространяемый за деньги. PVS-Studio работает только под Windows и только с Visual Studio. Есть многочисленные сведения о существовании Linux-версии, но на официальном сайте она не доступна. Насколько я понял, цена лицензии обсуждается индивидуально с каждым клиентом. Доступен триал.
Я протестировал PVS-Studio 6.02 на Windows 7 SP1 работающей под KVM с установленной Visual Studio 2013 Express Edition. Во время установки PVS-Studio также дополнительно скачался.NET Framework 4.6. Выглядит это примерно так. Вы открываете проект (я тестировал на PostgreSQL) в Visual Studio, в PVS-Studio жмете «сейчас я начну собирать проект», затем в Visual Studio нажимаете Build, по окончании сборки в PVS-Studio жмете «я закончил» и смотрите отчет.
PVS-Studio действительно находит очень крутые ошибки, которые Clang Static Analyzer не видит (например). Также очень понравился интерфейс, позволяющий сортировать и фильтровать ошибки по их типу, серьезности, файлу, в котором они были найдены, и так далее.
С одной стороны, печалит, что чтобы использовать PVS-Studio, проект должен уметь собираться под Windows. С другой стороны, использовать в проекте CMake и собирать-тестировать его под разными ОС, включая Windows, при любом раскладе является очень неплохой затеей. Так что, пожалуй, это не такой уж и большой недостаток. Кроме того, по следующим ссылкам можно найти кое-какие подсказки касательно того, как людям удавалось прогонять PVS-Studio на проектах, которые не собираются под Windows: раз , два , три , четыре .
Дополнение: Попробовал бета-версию PVS-Studio для Linux. Пользоваться ею оказалось очень просто . Создаем pvs.conf примерно такого содержания:
lic-file=/home/afiskon/PVS-Studio.lic
output-file=/home/afiskon/postgresql/pvs-output.log
Затем говорим:
make
clean
./
configure ...
pvs-studio-analyzer trace --
make
# будет создан большой (у меня ~40 Мб) файл strace_out
pvs-studio-analyzer analyze --cfg
./
pvs.conf
plog-converter -t
tasklist -o
result.task pvs-output.log
Дополнение: PVS-Studio для Linux вышел из беты и теперь доступен всем желающим .
Coverity Scan
Coverity считается одним из самых навороченных (а следовательно и дорогих) статических анализаторов. К сожалению, на официальном сайте невозможно скачать даже его триал-версию. Можно заполнить форму, и если вы какой-нибудь IBM, с вами может быть свяжутся. При очень сильном желании Coverity какой-нибудь доисторической версии можно найти через неофициальные каналы. Он бывает для Windows и Linux, работает примерно по тому же принципу, что и PVS-Studio. Но без серийника или лекарства отчеты Coverity вам не покажет. А чтобы найти серийник или лекарство, нужно иметь не просто очень сильное желание, а очень-очень-очень сильное.
К счастью, у Coverity есть SaaS версия — Coverity Scan. Мало того, что Coverity Scan доступен для простых смертных, он еще и совершенно бесплатен. Привязки к конкретной платформе нет. Однако анализировать с помощью Coverity Scan разрешается только открытые проекты.
Вот как это работает. Вы регистрируете свой проект через веб-интерфейс (или присоединяетесь к уже существующему, но это менее интересный кейс). Чтобы посмотреть отчеты, нужно пройти модерацию, которая занимает 1-2 рабочих дня.
Отчеты строятся таким образом. Сначала вы локально собираете свой проект под специальной утилитой Coverity Build Tool. Утилита эта аналогична scan-build из Clang Static Analyzer и доступна под все мыслимые платформы, включая всякую экзотику типа FreeBSD или даже NetBSD.
Установка Coverity Build Tool:
tar
-xvzf
cov-analysis-linux64-7.7.0.4.tar.gz
export
PATH
=/
home/
eax/
temp/
cov-analysis-linux64-7.7.0.4/
bin:$PATH
Готовим тестовый проект (я использовал код из заметки Продолжаем изучение OpenGL: простой вывод текста):
git clone
git
@
github.com:afiskon/
c-opengl-text.git
cd
c-opengl-text
git submodule
init
git submodule
update
mkdir
build
cd
build
cmake
..
Затем собираем проект под cov-build:
cov-build --dir cov-int make -j2 demo emdconv
Важно! Не меняйте название директории cov-int.
Архивируем директорию cov-int:
tar -cvzf c-opengl-text.tgz cov-int
Заливаем архив через форму Upload a Project Build. Также на сайте Coverity Scan есть инструкции по автоматизации этого шага при помощи curl. Ждем немного, и можно смотреть результаты анализа. Примите во внимание, что чтобы пройти модерацию, нужно отправить на анализ хотя бы один билд.
Ошибки Coverity Scan ищет очень хорошо. Уж точно лучше, чем Clang Static Analyzer. При этом ложно-положительные срабатывания есть, но их намного меньше. Что удобно, в веб-интерфейсе есть что-то вроде встроенного багтрекера, позволяющего присваивать ошибкам серьезность, ответственного за их исправление и подобные вещи. Видно, какие ошибки новые, а какие уже были в предыдущих билдах. Ложно-положительные срабатывания можно отметить как таковые и скрыть.
Заметьте, что чтобы проанализировать проект в Coverity Scan, не обязательно быть его владельцем. Мне лично вполне успешно удалось проанализировать код PostgreSQL без присоединения к уже существующему проекту. Думается также, что при сильном желании (например, используя сабмодули Git), можно подсунуть на проверку немного и не очень-то открытого кода.
Заключение
Вот еще несколько статических анализаторов, не попавших в обзор:
Каждый из рассмотренных анализаторов находят такие ошибки, которые не находят другие. Поэтому в идеале лучше использовать их сразу все. Делать это вот прямо постоянно, скорее всего, объективно не получится. Но делать хотя бы один прогон перед каждым релизом точно будет не лишним. При этом Clang Static Analyzer выглядит наиболее универсальным и при этом достаточно мощным. Если вас интересует один анализатор, который нужно обязательно использовать в любом проекте, используйте его. Но все же я бы рекомендовал дополнительно использовать как минимум PVS-Studio или Coverity Scan.
А какие статические анализаторы вы пробовали и/или регулярно использовали и каковы ваши впечатления от них?
У каждого из команды ][ - свои предпочтения по части софта и утилит для
пентеста. Посовещавшись, мы выяснили: выбор так разнится, что можно составить
настоящий джентльменский набор из проверенных программ. На том и решили. Чтобы
не делать сборную солянку, весь список разбит на темы. Сегодня мы разберем
статические анализаторы кода
для поиска уязвимостей в приложениях, когда на
руках – их исходники.
Наличие исходных кодов программы существенно упрощает поиск уязвимостей.
Вместо того чтобы вслепую манипулировать различными параметрами, которые
передаются приложению, куда проще посмотреть в сорцах, каким образом она их
обрабатывает. Скажем, если данные от пользователя передаются без проверок и
преобразований, доходят до SQL-запроса – имеем уязвимость типа SQL injection.
Если они добираются до вывода в HTML-код – получаем классический XSS. От
статического сканера требуется четко обнаруживать такие ситуации, но, к
сожалению, выполнить это не всегда так просто как кажется.
Современные компиляторы
Может показаться забавным, но одними из самых эффективных анализаторов
кода
являются сами компиляторы. Конечно, предназначены они совсем для
другого, но в качестве бонуса каждый из них предлагает неплохой верификатор
исходников, способный обнаружить большое количество ошибок. Почему же он не
спасает? Изначально настройки такой верификации кода выставлены достаточно
лояльно: в результате, чтобы не смущать программиста, компилятор начинает
ругаться только в случае самых серьезных косяков. А вот и зря - если поставить
уровень предупреждений повыше, вполне реально откопать немало сомнительных мест
в коде. Выглядит это примерно следующим образом. Скажем, в коде есть отсутствие
проверки на длину строки перед копированием ее в буфер. Сканер находит функцию,
копирующую строку (или ее фрагмент) в буфер фиксированного размера без
предварительной проверки ее длины. Он прослеживает траекторию передачи
аргументов: от входных данных до уязвимой функции и смотрит: возможно ли
подобрать такую длину строки, которая бы вызывала переполнение в уязвимой
функции и не отсекалась бы предшествующими ей проверками. В случае если такой
проверки нет, находим практически 100% переполнение буфера. Главная сложность в
использовании для проверки компилятора - заставить его "проглотить" чужой код.
Если ты хоть раз пытался скомпилировать приложение из исходников, то знаешь,
насколько сложно удовлетворить все зависимости, особенно в больших проектах. Но
результат стоит того! Тем более, помимо компилятора в мощные IDE встроены и
некоторые другие средства для анализа кода
. К примеру, на следующий
участок кода в Visual Studio будет выдано предупреждение об использовании в
цикле функции _alloca, что может быстро переполнить стек:
char *b;
do {
b = (char*)_alloca(9)
} while(1)
В этом заслуга статического анализатора PREfast. Подобно FxCop,
предназначенной для анализа управляемого кода, PREfast изначально
распространялся в виде отдельной утилиты и лишь позже стал частью Visual Studio.
RATS - Rough Auditing Tool for Security
Сайт: www.securesoftware.com
Лицензия: GNU GPL
Платформа: Unix, Windows
Языки: С++, PHP, Python, Ruby
Ошибка ошибке - рознь. Часть тех огрех, которые допускают программисты,
некритична и грозит только нестабильностью программы. Другие, напротив,
позволяют инжектировать шелл-код и выполнять произвольные команды на удаленном
сервере. Особый риск в коде представляют команды, позволяющие выполнить buffer
overflow и другие похожие типы атак. Таких команд очень много, в случае с C/C++
это функции для работы со строками (xstrcpy(), strcat(), gets(), sprintf(),
printf(), snprintf(), syslog()), системные команды (access(), chown(), chgrp(),
chmod(), tmpfile(), tmpnam(), tempnam(), mktemp()), а также команды системных
вызовов (exec(), system(), popen()). Вручную исследовать весь код (особенно,
если он состоит из нескольких тысяч строк) довольно утомительно. А значит, можно
без труда проглядеть передачу какой-нибудь функции непроверенных параметров.
Значительно облегчить задачу могут специальные средства для аудита, в том числе,
известная утилита RATS
(Rough Auditing Tool for Security
) от
известной компании Fortify. Она не только успешно справится с обработкой кода,
написанного на C/C++, но сможет обработать еще и скрипты на Perl, PHP и Python.
В базе утилиты находится внушающая подборка с детальным описанием проблемных
мест в коде. С помощью анализатора она обработает скормленный ей сорец и
попытается выявить баги, после чего выдаст информацию о найденных недочетах.
RATS
работает через командную строку, как под Windows, так и *nix-системами.
Yasca
Сайт: www.yasca.org
Лицензия: Open Source
Платформа: Unix, Windows
Языки: С++, Java, .NET, ASP, Perl, PHP, Python и другие.
Yasca
так же, как и RATS не нуждается в установке, при этом имеет не
только консольный интерфейс, но и простенький GUI. Разработчики рекомендуют
запускать утилиту через консоль - мол, так возможностей больше. Забавно, что
движок Yasca написан на PHP 5.2.5, причем интерпретатор (в самом урезанном
варианте) лежит в одной из подпапок архива с программой. Вся программа логически
состоит из фронт-енда, набора сканирующих плагинов, генератора отчета и
собственно движка, который заставляет все шестеренки вращаться вместе. Плагины
свалены в директорию plugins - туда же нужно устанавливать и дополнительные
аддоны. Важный момент! Трое из стандартных плагинов, которые входят в состав
Yasca
, имеют неприятные зависимости. JLint, который сканирует Java"овские
.class-файлы, требует наличия jlint.exe в директории resource/utility. Второй
плагин - antiC, используемый для анализа сорцов Java и C/C++, требует antic.exe
в той же директории. А для работы PMD, который обрабатывает Java-код, необходима
установленная в системе Java JRE 1.4 или выше. Проверить правильность установки
можно, набрав команду "yasca ./resources/test/". Как выглядит сканирование?
Обработав скормленные программе сорцы, Yasca
выдает результат в виде
специального отчета. Например, один из стандартных плагинов GREP позволяет с
помощью паттернов, описанных в.grep файлах, указать уязвимые конструкции и
легко выявлять целый ряд уязвимостей. Набор таких паттернов уже включен в
программу: для поиска слабого шифрования, авторизации по "пароль равен логину",
возможные SQL-инъекции и много чего еще. Когда же в отчете захочется увидеть
более детальную информации, не поленись установить дополнительные плагины. Чего
стоит одно то, что с их помощью можно дополнительно просканировать код на на
.NET (VB.NET, C#, ASP.NET), PHP, ColdFusion, COBOL, HTML, JavaScript, CSS,
Visual Basic, ASP, Python, Perl.
Cppcheck
Сайт:
Лицензия: Open Source
Платформа: Unix, Windows
Языки: С++
Разработчики Cppcheck
решили не разбрасываться по мелочам, а потому
отлавливают только строго определенные категории багов и только в коде на С++.
Не жди, что программа продублирует предупреждения компилятора - он обойдется без
суфлера. Поэтому не поленись поставить для компилятора максимальный уровень
предупреждений, а с помощью Cppcheck проверь наличие утечек памяти, нарушений
операций allocation-deallocation, различных переполнений буфера, использования
устаревших функций и многого другого. Важная деталь: разработчики Cppcheck
постарались свести количество ложных срабатываний к минимуму. Поэтому, если
прога фиксирует ошибку, можно с большой вероятностью сказать: "Она действительно
есть!" Запустить анализ можно как из-под консоли, так и с помощью приятного
GUI-интерфейса, написанного на Qt и работающего под любой платформой.
graudit
Сайт:
www.justanotherhacker.com/projects/graudit.html
Лицензия: Open Source
Платформа: Unix, Windows
Языки: C++, PHP, Python, Perl
Этот простой скрипт, совмещенный с набором сигнатур, позволяет найти ряд
критических уязвимостей в коде, причем поиск осуществляется с помощью всем
известной утилиты grep. О GUI-интерфейсе тут неуместно даже упоминать: все
осуществляется через консоль. Для запуска есть несколько ключей, но в самом
простом случае достаточно указать в качестве параметра путь к исходникам:
graudit /path/to/scan
Наградой за старание будет цветастый отчет о потенциально эксплуатируемых
местах в коде. Надо сказать, что, помимо самого скрипта (а это всего 100 строчек
кода на Bash), ценность представляют сигнатурные базы, в которых собраны
регекспы и названия потенциально уязвимых функций в разных языках. По умолчанию
включены базы для Python, Perl, PHP, C++ - можно взять файлы из папки signatures
и использовать в своих собственных разработках.
SWAAT
Сайт: www.owasp.org
Лицензия: Open Source
Платформа: Unix, Windows
Языки: Java, JSP, ASP .Net, PHP
Если в graudit для задания сигнатуры уязвимости используются текстовые файлы,
то в SWAAT
– более прогрессивный подход с помощью XML-файлов. Вот так
выглядит типичная сигнатура:
vuln match - регулярное выражение для поиска;
type - указывает на тип уязвимости:
severity - обозначает уровень риска (high, medium или low)
alt - альтернативный вариант кода для решения проблемы
SWAAT
считывает базу сигнатур и с ее помощью пытается найти проблемные
участки кода в исходниках на Java, JSP, ASP .Net, и PHP. База постоянно
пополняется и помимо списка "опасных" функций, сюда включены типичные ошибки в
использовании форматирования строк и составлении SQL-запросов. Примечательно,
что прога написана на C#, однако отлично работает и под никсами, благодаря
проекту Mono - открытой реализации платформы.Net.
PHP Bug Scanner
Сайт:
raz0r.name/releases/php-bug-scanner
Лицензия: Freeware
Платформа: Windows
Языки: PHP
Если тебе нужно провести статический анализ PHP-приложения, рекомендую
попробовать PHP Bug Scanner
, которую написал наш автор - raz0r. Работа
проги основана на сканировании различных функций и переменных в PHP-скриптах,
которые могут быть задействованы при проведении веб-атак. Описание таких
ситуаций оформляется в виде так называемых пресетов, причем в программу уже
включены 7 специальных прессетов, сгруппированных по категориям:
- code execution;
- command execution;
- directory traversal;
- globals overwrite;
- include;
- SQL-injection;
- miscellaneous.
Забавно, что прога написана на
PHP/WinBinder и скомпилирована
bamcompile , поэтому выглядит так же, как и обычное Windows-приложение. Через
удобный интерфейс пентестер может включить или отключь анализ кода на наличие
тех или иных уязвимостей.
Pixy
Сайт:
pixybox.seclab.tuwien.ac.at
Лицензия: Freeware
Платформа: Unix, Windows
Языки: PHP
В основе работы инструмента - сканирование исходного кода и построение графов
потоков данных. По такому графу прослеживается путь данных, которые поступают
извне программы - от пользователя, из базы данных, от какого-нибудь внешнего
плагина и т.п. Таким образом строится список уязвимых точек (или входов) в
приложениях. С помощью паттернов, описывающих уязвимость, Pixy проверяет такие
точки и позволяет определить XSS- и SQL-уязвимости. Причем сами графы, которые
строятся во время анализа, можно посмотреть в папке graphs (например,
xss_file.php_1_dep.dot) - это очень полезно для того чтобы понять, почему именно
тот или иной участок кода считается Pixy-уязвимым. Вообще, сама разработка
крайне познавательна и демонстрирует, как работают продвинутые утилиты для
статического анализа кода. На страничке
документации разработчик доходчиво рассказывает о разных этапах работы
программы, объясняет логику и алгоритм того, как должен анализироваться прогой
тот или иной фрагмент кода. Сама программа написана на Java и распространяется в
открытых исходниках, а на домашней страничке есть даже простенький онлайн-сервис
для проверки кода на XSS-уязвимости.
Ounce 6
Сайт: www.ouncelabs.com/products
Лицензия: Shareware
Платформа: Windows
Увы, существующие бесплатные решения пока на голову ниже, чем коммерческие
аналоги. Достаточно изучить качество и детальность отчета, который составляет
Ounce 6
– и понять, почему. В основе программы лежит специальный
анализирующий движок Ounce Core, который проверяет код на соответствие правилам
и политикам, составленными командой профессиональных пентестеров,
аккумулировавших опыт известных security-компаний, хакерского комьюнити, а также
стандартов безопасности. Программа определяет самые разные уязвимости в коде: от
переполнения буфера до SQL-инъекций. При желании Ounce несложно интегрируется с
популярными IDE, чтобы реализовать автоматическую проверку кода во время сборки
каждого нового билда разрабатываемого приложения. Кстати говоря,
компанию-разработчика - Ounce Labs - летом этого года приобрела сама IBM. Так
что продукт, скорее всего, продолжит развитие уже как часть одного из
коммерческих приложений IBM.
Klocwork Insight
Сайт: www.klocwork.com
Лицензия: Shareware
Платформа: Windows
Языки: C++, Java, C#
Долгое время этот, опять же, коммерческий продукт реализовал статическое
сканирование кода только для C, C+ и Java. Но, как только вышли Visual Studio
2008 и.NET Framework 3.5, разработчики заявили о поддержке C#. Я прогнал
программу на двух своих вспомогательных проектах, которые на скорую руку написал
на "шарпе" и программа выявила 7 критических уязвимостей. Хорошо, что они
написаны исключительно для внутреннего использования:). Klocwork Insight
изначально настроен, прежде всего, на работу в связке с интегрированными средами
разработки. Интеграция с теми же Visual Studio или Eclipse выполнена чрезвычайно
удачно – начинаешь всерьез задумываться, что такая функциональность должна быть
реализована в них по умолчанию:). Если не брать в расчет проблемы с логикой
работы приложения и проблемы с быстродействием, то Klocwork Insight
отлично справляется с поиском переполнения буфера, отсутствия фильтрации
пользовательского кода, возможности SQL/Path/Cross-site инъекций, слабого
шифрования и т.п. Еще одна интересная опция – построение дерева выполнения
приложения, позволяющего быстро вникнуть в общий принцип работы приложения и
отдельно проследить, например, за обработкой какого-либо пользовательского
ввода. А для быстрого конструирования правил для проверки кода предлагается даже
специальный инструмент - Klocwork Checker Studio
.
Coverity Prevent Static Analysis
Сайт: www.coverity.com/products
Лицензия: Shareware
Платформа: Windows
Языки: C++, Java, C#
Один из самых известных статических анализаторов кода на C/C++, Java и C#.
Если верить его создателям, – решение используется более чем 100.000
разработчиков по всему миру. Продуманные механизмы позволяют автоматизировать
поиск утечек памяти, неотловленных исключений, проблем с быстродействием и,
конечно же, уязвимостей в безопасности. Продукт поддерживает разные платформы,
компиляторы (gcc, Microsoft Visual C++ и многие другие), а также интегрируется с
различными средами разработки, прежде всего Eclipse и Visual Studio. В основе
обхода кода используются не тупые алгоритмы обхода от начала до конца, а что-то
вроде отладчика, анализирующего, как программа поведет в себя в различных
ситуациях после встречи ветвления. Таким образом достигается 100% покрытия кода.
Столь сложный подход потребовался в том числе, чтобы всецело анализировать
многопоточные приложения, специально оптимизированные для работы на многоядерных
процессорах. Coverity Integrity Center
позволяет находить такие ошибки
как состояние гонки (ошибка проектирования многозадачной системы, при которой
работа системы зависит от того, в каком порядке выполняются части кода), тупики
и многое другое. Зачем это нужно реверсерам? Спроси об этом разработчиков 0day
сплоитов для Firefox и IE:).
OWASP Code Crawler
Сайт: www.owasp.org
Лицензия: GNU GPL
Платформа: Windows
Языки: Java, C#, VB
Создатель этой тулзы Алессио Марциали - автор двух книжек по ASP.NET,
авторитетный кодер высоконагруженных приложений для финансового сектора, а также
пентестер. В 2007 году он опубликовал информацию о критических уязвимостях в 27
правительственных сайтах Италии. Его детище – OWASP Code Crawler
–
предназначенное для статического анализа кода.NET и J2EE/JAVA, открыто доступно
в инете, а в конце года автор обещается выпустить новую версию программы с
намного большей функциональностью. Но самое-то главное реализовано уже сейчас –
анализ исходников на C#, Visual Basic и Java. Файлы для проверки выбираются
через GUI-интерфейс, а сканирование запускается автоматически. Для каждого
проблемного участка кода выводится описание уязвимости в разделе Threat
Description. Правда, поле OWASP Guidelines
, вероятно, указывающее пути
решения проблемы, увы, пока не доступно. Зато можно воспользоваться
экспериментальной особенностью сканирования кода на удаленной машине, доступной
во вкладке Remote Scan. Автор обещает серьезно прокачать эту возможность и, в
том числе, агрегировать исходники приложения для анализа прямо из системы
контроля версий.
WARNING
Информация представлена в целях ознакомления и, прежде всего, показывает,
каким образом разработчики могут избежать критических ошибок во время разработки
приложений. За использование полученных знаний в незаконных целях ни автор, ни
редакция ответственности не несут.
При статическом анализе (static analysis) можно обнаружить много разнообразных дефектов и слабых мест исходного кода даже до того, как код будет готов для запуска. С другой стороны, динамический анализ (runtime analysis), или анализ во время выполнения, происходит на работающем программном обеспечении и обнаруживает проблемы по мере их возникновения, обычно используя сложные инструментальные средства. Кто-то может возразить, что одна форма анализа предваряет другую, но разработчики могут комбинировать оба способа для ускорения процессов разработки и тестирования, а также для повышения качества выдаваемого продукта.
В данной статье вначале рассматривается метод статического анализа. С его помощью можно предотвратить проблемы до их проникновения в состав основного программного кода и гарантировать, что новый код соответствует стандарту. Используя разные техники анализа, например, проверку абстрактного синтаксического дерева (abstract syntax tree, AST) и анализ кодовых путей, инструменты статического анализа могут выявить скрытые уязвимости, логические ошибки, дефекты реализации и другие проблемы. Это может происходить как на этапе разработки на каждом рабочем месте, так и во время компоновки системы. Далее в статье исследуется метод динамического анализа, который можно использовать на этапе разработки модулей и системной интеграции и который позволяет выявить проблемы, пропущенные при статическом анализе. При динамическом анализе не только обнаруживаются ошибки, связанные с указателями и другими некорректностями, но и есть возможность также оптимизировать использование циклов ЦПУ, ОЗУ, флеш-памяти и других ресурсов.
В статье обсуждаются также варианты комбинирования статического и динамического анализа, что поможет предотвращать возврат к более ранним этапам разработки по мере "созревания" продукта. Такой подход с использованием сразу двух методик помогает избежать проявления большинства проблем еще на ранних этапах разработки, когда их легче и дешевле всего исправить.
Объединяя лучшее из двух миров
Инструменты статического анализа находят программные ошибки еще на ранней фазе создания проекта, обычно перед тем, как создается исполняемый файл. Такое раннее обнаружение особенно полезно для проектов больших встраиваемых систем, где разработчики не могут использоваться средства динамического анализа до тех пор, пока программное обеспечение не будет завершено настолько, чтобы его было можно запустить на целевой системе.
На этапе статического анализа обнаруживаются и описываются области исходного кода со слабыми местами, включая скрытые уязвимости, логические ошибки, дефекты реализации, некорректности при выполнении параллельных операций, редко возникающие граничные условия и многие другие проблемы. Например, инструменты статического анализа Klocwork Insight выполняют глубокий анализ исходного кода на синтаксическом и семантическом уровнях. Эти инструментальные средства выполняют также сложный межпроцедурный анализ управляющих потоков и потоков данных и используют усовершенствованную технику отсекания ложных путей, оценивают значения, которые будут принимать переменные и моделируют потенциальное поведение программы во время исполнения.
Разработчики могут использовать инструменты статического анализа в любое время на этапе разработки, даже когда написаны лишь фрагменты проекта. Однако чем более завершенным является код, тем лучше. При статическом анализе могут просматриваться все потенциальные пути исполнения кода – при обычном тестировании такое происходит редко, если только в проекте не требуется обеспечения 100%-го покрытия кода. Например, при статическом анализе можно обнаружить программные ошибки, связанные с краевыми условиями или ошибками путей, не тестируемыми во время разработки.
Поскольку во время статического анализа делается попытка предсказать поведение программы, основанное на модели исходного кода, то иногда обнаруживается "ошибка", которой фактически не существует – это так называемое "ложное срабатывание" (false positive). Многие современные средства статического анализа реализуют улучшенную технику, чтобы избежать подобной проблемы и выполнить исключительно точный анализ.
| Статический анализ: аргументы "за" | Статический анализ: аргументы "против" |
|
Используется уже на ранних этапах жизненного цикла программного обеспечения, прежде чем код готов для исполнения и до начала тестирования.
Могут анализироваться существующие базы кодов, которые уже прошли тестирование. Средства могут быть интегрированы в среду разработки в качестве части компонента, используемого при "ночных сборках" (nightly builds) и как часть инструментального набора рабочего места разработчика. Низкие стоимостные затраты: нет необходимости создавать тестовые программы или фиктивные модули (stubs); разработчики могут запускать свои собственные виды анализа. |
Могут обнаруживаться программные ошибки и уязвимости, которые не обязательно приводят к отказу программы или воздействуют на поведение программы во время ее реального исполнения.
Ненулевая вероятность "ложного срабатывания". |
Таблица 1 - Аргументы "за" и "против" статического анализа.
Инструменты динамического анализа обнаруживают программные ошибки в коде, запущенном на исполнение. При этом разработчик имеет возможность наблюдать или диагностировать поведение приложения во время его исполнения, в идеальном случае – непосредственно в целевой среде.
Во многих случаях в инструменте динамического анализа производится модификация исходного или бинарного кода приложения, чтобы установить ловушки, или процедуры-перехватчики (hooks), для проведения инструментальных измерений. C помощью этих ловушек можно обнаружить программные ошибки на этапе выполнения, проанализировать использование памяти, покрытие кода и проверить другие условия. Инструменты динамического анализа могут генерировать точную информацию о состоянии стека, что позволяет отладчикам отыскать причину ошибки. Поэтому, когда инструменты динамического анализа находят ошибку, то, скорее всего, это настоящая ошибка, которую программист может быстро идентифицировать и исправить. Следует заметить, что для создания ошибочной ситуации на этапе выполнения должны существовать точно необходимые условия, при которых проявляется программная ошибка. Соответственно, разработчики должны создать некоторый контрольный пример для реализации конкретного сценария.
| Динамический анализ: аргументы "за" | Динамический анализ: аргументы "против" |
|
Редко возникают "ложные срабатывания" – высокая продуктивность по нахождению ошибок
Для отслеживания причины ошибки может быть произведена полная трассировка стека и среды исполнения. Захватываются ошибки в контексте работающей системы, как в реальных условиях, так и в режиме имитационного моделирования. |
Происходит вмешательство в поведение системы в реальном времени; степень вмешательства зависит количества используемых инструментальных вставок. Это не всегда приводит к возникновению проблем, но об этом нужно помнить при работе с критическим ко времени кодом.
Полнота анализа ошибок зависит от степени покрытия кода. Таким образом, кодовый путь, содержащий ошибку, должен быть обязательно пройден, а в контрольном примере должны создаваться необходимые условия для создания ошибочной ситуации. |
Таблица 2 - Аргументы "за" и "против" динамического анализа.
Раннее обнаружение ошибок для уменьшения затрат на разработку
Чем раньше обнаруживается программная ошибка, тем быстрее и дешевле ее можно исправить. Поэтому инструменты статического и динамического анализа представляют реальную ценность, обеспечивая поиск ошибок на ранних этапах жизненного цикла программного обеспечения. Различные исследования промышленных продуктов показывают, что коррекция проблемы на этапе тестирования системы (для подтверждения качества ее работы, QA) или уже после поставки системы оказывается на несколько порядков более дорогостоящей, чем устранение тех же проблем на этапе разработки программного обеспечения. Многие организации имеют свои оценочные показатели относительно затрат на устранение дефектов. На рис. 1 приведены данные по обсуждаемой проблеме, взятые из часто цитируемой книги Каперса Джонса (Capers Jones) "Applied Software Measurement" ("Прикладные измерения программного обеспечения") .
Рис. 1 - По мере продвижения проекта стоимость устранения дефектов программного обеспечения может экспоненциально возрастать. Инструменты статического и динамического анализа помогают предотвратить эти затраты благодаря обнаружению программных ошибок на ранних этапах жизненного цикла программного обеспечения.
Статический анализ
Статический анализ используется в практике программных разработок почти столь же долго, как существует сама разработка программного обеспечения. В своем первоначальном виде анализ сводился к контролю соответствия стандартам стиля программирования (lint). Разработчики пользовались этим непосредственно на своем рабочем месте. Когда дело доходило до обнаружения программных ошибок, то в ранних инструментах статического анализа основное внимание обращалось на то, что лежит на поверхности: стиль программирования и часто возникающие синтаксические ошибки. Например, даже самые простейшие инструменты статического анализа смогут обнаружить ошибку такого рода:
Int foo(int x, int* ptr) { if(x & 1); { *ptr = x; return; } ... }
Здесь ошибочное употребление лишней точки с запятой приводит к потенциально катастрофическим результатам: указатель входного параметра функции переопределяется при неожидаемых условиях. Указатель переопределяется всегда, вне зависимости от проверяемого условия.
Ранние инструменты анализа обращали внимание, главным образом, на синтаксические ошибки. Поэтому, хотя при этом и можно было обнаружить серьезные ошибки, все же большинство обнаруживаемых проблем оказывались относительно тривиальными. Кроме того, для инструментов предоставлялся достаточно небольшой кодовый контекст, чтобы можно было ожидать точных результатов. Это происходило потому, что работа проводилась в течение типичного цикла компиляции/компоновки при разработке, а то, что делал разработчик, представляло собой лишь маленькую частицу кода большой программной системы. Такой недостаток приводил к тому, что в инструменты анализа закладывались оценки и гипотезы относительно того, что может происходить за пределами "песочницы" разработчика. А это, в свою очередь, приводило к генерации повышенного объема отчетов с "ложными срабатываниями".
Следующие поколения инструментов статического анализа обращали внимание на эти недостатки и расширяли сферу своего влияния за пределы синтаксического и семантического анализа. В новых инструментах строилось расширенное представление или модель создаваемого кода (нечто похожее на фазу компиляции), а далее моделировались все возможные пути исполнения кода в соответствии с моделью. Далее производилось отображение на эти пути логических потоков с одновременным контролем того, как и где создаются, используются и уничтожаются объекты данных. В процессе анализа программных модулей могут подключаться процедуры анализа межпроцедурного управления и потока данных. При этом также минимизируются "ложные срабатывания" за счет использования новых подходов для отсекания ложных путей, оценки значений, которые могут принимать переменные, моделирования потенциального поведения при работе в реальном времени. Для генерации данных такого уровня в инструментах статического анализа необходимо анализировать всю кодовую базу проекта, проводить интегральную системную компоновку, а не просто работать с результатами, получаемыми в "песочнице" на рабочем столе разработчика.
Для выполнения таких изощренных форм анализа в инструментах статического анализа имеют дело с двумя основными типами проверок кода:
- Проверка абстрактного синтаксического дерева - для проверки базового синтаксиса и структуры кода.
- Анализ кодовых путей - для выполнения более полного анализа, который зависит от понимания состояния программных объектов данных в конкретной точке на пути исполнения кода.
Абстрактные синтаксические деревья
Абстрактное синтаксическое дерево просто является представлением исходного кода в виде древовидной структуры, как это может генерироваться на предварительных стадиях работы компилятора. Дерево содержит подробное однозначное разложение структуры кода, дающее возможность инструментам выполнить простой поиск аномальных мест синтаксиса.
Очень просто построить программу контроля, которая проверяет соблюдение стандартов относительно соглашения по присваиванию имен и ограничений по функциональным вызовам, например, контроль небезопасных библиотек. Цель выполнения проверок по AST обычно состоит в получении каких-либо логических выводов на основании кода как такового без использования знаний о поведении кода в процессе исполнения.
Многие инструменты предлагают проверки на основе AST для множества языков, включая инструменты с открытым исходным кодом, например, PMD для Java. Некоторые инструменты используют грамматику Х-путей или производную от Х-путей грамматику, чтобы определять условия, которые представляют интерес для программ контроля. Другие инструменты предоставляют расширенные механизмы, дающие возможность пользователям создавать свои собственные программы проверки на основе AST. Такой тип проверки относительно просто проводить, и многие организации создают новые программы проверки такого типа, чтобы проверить соблюдение корпоративных стандартов написания кода или рекомендованных по отрасли лучших методов организации работ.
Анализ кодовых путей
Рассмотрим более сложный пример. Теперь вместо поиска случаев нарушения стиля программирования мы хотим проверить, приведет ли предпринятая попытка разыменования указателя к правильной работе или к сбою:
If(x & 1) ptr = NULL; *ptr = 1;
Поверхностное рассмотрение фрагмента приводит к очевидному выводу, что переменная ptr может принимать значение NULL, если переменная x – нечетна, и это условие при разыменовании неизбежно приведет к обращению к нулевой странице. Тем не менее, при создании программы проверки на основе AST найти такую программную ошибку весьма проблематично. Рассмотрим дерево AST (в упрощенном виде для ясности), которое было бы создано для приведенного выше фрагмента кода:
Statement Block If-statement Check-Expression Binary-operator & x 1 True-Branch Expression-statement Assignment-operator = ptr 0 Expression-statement Assignment-operator = Dereference-pointer - ptr 1 В подобных случаях никакой поиск по дереву или простое перечисление узлов не смогут обнаружить в разумно обобщенной форме предпринимаемую попытку (по меньшей мере, иногда недопустимую) разыменования указателя ptr. Соответственно, инструмент анализа не может просто проводить поиск по синтаксической модели. Необходимо также анализировать жизненный цикл объектов данных по мере их появления и использования внутри управляющей логики в процессе исполнения.
При анализе кодовых путей прослеживаются объекты внутри путей исполнения, в результате чего программы проверки могут определить, насколько четко и корректно используются данные. Использование анализа кодовых путей расширяет круг вопросов, на которые могут быть получены ответы в процессе проведения статического анализа. Вместо того чтобы просто анализировать правильность написания кода программы, при анализе кодовых путей делается попытка определить "намерения" кода и проверить, написан ли код в соответствии с этими намерениями. При этом могут быть получены ответы на следующие вопросы:
- Не был ли вновь созданный объект освобожден прежде, чем из области видимости были удалены все обращающиеся к нему ссылки?
- Проводилась ли для некоторого объекта данных проверка разрешенного диапазона значений, прежде чем объект передается функции ОС?
- Проверялась ли строка символов на наличие в ней специальных символов перед передачей этой строки в качестве SQL-запроса?
- Не приведет ли операция копирования к переполнению буфера?
- Безопасно ли в данное время вызывать эту функцию?
Посредством подобного анализа путей исполнения кода, как в прямом направлении от запуска события к целевому сценарию, так и в обратном направлении от запуска события к требуемой инициализации данных, инструментальное средство сможет дать ответы на поставленные вопросы и выдать отчет об ошибках в случае, если целевой сценарий или инициализация исполняются или не исполняются так, как ожидается.
Реализация подобной возможности существенна для выполнения расширенного анализа исходного кода. Поэтому разработчики должны искать инструменты, в которых используется расширенный анализ кодовых путей для обнаружения утечек памяти, неправильного разыменования указателей, передачи небезопасных или неправильных данных, нарушений параллелизма и многих других условий, приводящих к возникновению проблем.
Последовательность действий при выполнении статического анализа
При статическом анализе могут быть обнаружены проблемы в двух ключевых точках процесса разработки: во время написания программе на рабочем месте и на этапе системной компоновки. Как уже говорилось, текущее поколение инструментальных средств работает, главным образом, на этапе системной компоновки, когда есть возможность проанализировать кодовый поток всей системы в целом, что приводит к весьма точным диагностическим результатам.
Уникальный в своем роде продукт Klocwork Insight позволяет проводить анализ кода, создаваемого на рабочем месте конкретного разработчика, при этом избегать проблем, связанных с неточностью диагностики, что обычно свойственно инструментам подобного рода. Компания Klocwork предоставляет возможность проведения связного анализа кода на рабочем месте (Connected Desktop Analysis), когда выполняется анализ кода разработчика с учетом понимания всех системных зависимостей. Это приводит к проведению локального анализа, который является в такой же мере точным и мощным, как и централизованный системный анализ, но все это выполняется до полной сборки кода.
С точки зрения перспектив относительно последовательности действий при анализе, данная способность позволяет разработчику провести точный и высококачественный статический анализ на самом раннем этапе жизненного цикла разработки. Инструмент Klockwork Insight выдает в интегрированную среду разработчика (IDE) или в командную строку сообщения по всем проблемам по мере написания разработчиком кода и периодического выполнения им операций компиляции/компоновки. Выдача таких сообщений и отчетов происходит до выполнения динамического анализа и до того, как все разработчики сведут свои коды воедино.
Рис. 2 - Последовательность выполнения статического анализа.Технология динамического анализа
Для обнаружения программных ошибок в инструментах динамического анализа часто производится вставка небольших фрагментов кода либо непосредственно в исходный текст программы (вставка в исходный код), либо в исполняемый код (вставка в объектный код). В таких кодовых сегментах выполняется "санитарная проверка" состояния программы и выдается отчет об ошибках, если обнаруживается что-то некорректное или неработоспособное. В таких инструментах могут быть задействованы и другие функции, например, отслеживание распределения памяти и ее использования во времени.
Технология динамического анализа включает в себя:
- Размещение вставок в исходный код на этапе препроцессорной обработки – в исходный текст приложения до начала компиляции вставляется специальный фрагмент кода для обнаружения ошибок. При таком подходе не требуется детального знания среды исполнения, в результате чего такой метод пользуется популярностью среди инструментов тестирования и анализа встраиваемых систем. В качестве примера такого инструмента можно привести продукт IBM Rational Test RealTime.
- Размещение вставок в объектный код – для такого инструмента динамического анализа необходимо обладать достаточными знаниями относительно среды исполнения, чтобы иметь возможность вставлять код непосредственно в исполняемые файлы и библиотеки. При этом подходе не нужно иметь доступа к исходному тексту программы или делать перекомпоновку приложения. В качестве примера такого инструмента можно привести продукт IBM Rational Purify.
- Вставка кода во время компиляции – разработчик использует специальные ключи (опции) компилятора для внедрения в исходный код. Используется способность компилятора обнаруживать ошибки. Например, в компиляторе GNU C/C++ 4.x используется технология Mudflap для выявления проблем, касающихся операций с указателями.
- Специализированные библиотеки этапа исполнения – для обнаружения ошибок в передаваемых параметрах разработчик использует отладочные версии системных библиотек. Дурной славой пользуются функции типа strcpy() из-за возможности появления нулевых или ошибочных указателей во время исполнения. При использовании отладочных версий библиотек такие "плохие" параметры обнаруживаются. Данная технология не требует перекомпоновки приложения и в меньшей степени влияет на производительность, чем полноценное использование вставок в исходный/объектный код. Данная технология используется в инструменте анализа ОЗУ в QNX® Momentics® IDE.
В данной статье мы рассмотрим технологии, используемые в инструментах разработчика QNX Momentics, особенно обращая внимание на GCC Mudflap и специализированные библиотеки этапа исполнения.
GNU C/C++ Mudflap: внедрение в исходный код на этапе компиляции
В инструментальном средстве Mudflap, присутствующем в версии 4.х компилятора GNU C/C++ (GCC), используется внедрение в исходный код во время компиляции. При этом во время исполнения происходит проверка конструкций, потенциально несущих в себе возможность появления ошибок. Основное внимание в средстве Mudflap обращается на операции с указателями, поскольку они являются источником многих ошибок на этапе выполнения для программ, написанных на языках C и C++.
С подключением средства Mudflap в работе компилятора GCC появляется еще один проход, когда вставляется проверочный код для операций с указателями. Вставляемый код обычно выполняет проверку на достоверность значений передаваемых указателей. Неправильные значения указателей приведут к выдаче компилятором GCC сообщений на стандартное устройство выдачи ошибок консоли (stderr). Средство Mudflap для контроля за указателями не просто проверяет указатели на нулевое значение: в его базе данных хранятся адреса памяти для действительных объектов и свойства объектов, например, местоположение в исходном коде, метка даты/времени, обратная трассировка стека при выделении и освобождении памяти. Такая база данных позволяет быстро получить необходимые данные при анализе операций доступа к памяти в исходном коде программы.
В библиотечных функциях, подобных strcpy(), не выполняется проверка передаваемых параметров. Такие функции не проверяются и средством Mudflap. Тем не менее, в Mudflap можно создать символьную оболочку (symbol wrapper) для статически подключаемых библиотек или вставку для динамических библиотек. При такой технологии между приложением и библиотекой создается дополнительный слой, что дает возможность провести проверку достоверности параметров и выдать сообщение о проявлении отклонений. В средстве Mudflap используется эвристический алгоритм, основанный на знании границ памяти, используемых приложением (динамическая память, стек, сегменты кода и данных и т.д.), чтобы определить правильность значений возвращаемых указателей.
Используя ключи командной строки компилятора GCC, разработчик может подключить возможности Mudflap для вставки кодовых фрагментов и управления поведением, например, управление нарушениями (границ, значений), проведение дополнительных проверок и настроек, подключение эвристических методов и самодиагностики. Например, комбинация ключей -fmudflap устанавливает конфигурацию Mudflap по умолчанию. Сообщения компилятора о выявленных средством Mudflap нарушениях выдаются на выходную консоль (stderr) или в командную строку. В подробном выводе предоставляется информация о нарушении и о задействованных при этом переменных, функциях, а также о местонахождении кода. Эта информация может автоматически импортироваться в среду IDE, где происходит ее визуализация, и выполняется трассировка стека. Пользуясь этими данными, разработчик может быстро перейти к соответствующему месту исходного кода программы.
На рис. 3 показан пример представления ошибки в среде IDE вместе с соответствующей информацией по обратной трассировке. Обратная трассировка работает как связующее звено с исходным кодом, что позволяет разработчику быстро диагностировать причину проблемы.
При использовании средства Mudflap может возрасти время на компоновку, и может уменьшиться производительность во время исполнения. Данные, представленные в статье “Mudflap: Pointer Use Checking for C/C++” ("Средство Mudflap: проверка использования указателей для языков C/C++”) говорят о том, что с подключением Mudflap время компоновки возрастает в 3…5 раз, а программа начинает работать медленнее в 1.25 … 5 раз. Совершенно ясно, что разработчики критических по времени исполнения приложений должны пользоваться эти средством с осторожностью. Тем не менее Mudflap является мощным средством для выявления подверженных ошибкам и потенциально фатальных кодовых конструкций. Компания QNX планирует использовать средство Mudflap в будущих версиях своих инструментов динамического анализа.

Рис. 3 - Использование информации обратной трассировки, отображаемой в среде QNX Momentics IDE для поиска исходного кода, приведшего к ошибке.
Отладочные версии библиотек этапа исполнения
Наряду с использованием специальных отладочных вставок в библиотеки этапа исполнения, которые приводят к значительным дополнительным расходам памяти и времени на этапах компоновки и исполнения, разработчики могут использовать предварительно подготовленные (pre-instrumented) библиотеки этапа исполнения. В таких библиотеках вокруг функциональных вызовов добавляется определенный код, цель которого состоит в проверке достоверности входных параметров. Например, рассмотрим старую знакомую – функцию копирования строк:
strcpy(a,b);
В ней участвуют два параметра, оба являющиеся указателями на тип char : один для исходной строки (b ), а другой для строки-результата (a ). Несмотря на такую простоту, эта функция может являться источником множества ошибок:
- если значение указателя a равно нулю или является недействительным, то копирование по этому адресу назначения приведет к ошибке запрета доступа к памяти;
- если значение указателя b равно нулю или является недействительным, то чтение информации с этого адреса приведет к ошибке запрета доступа к памяти;
- если в конце строки b пропущен завершающий строку символ "0", то в строку назначения будет скопировано большее число символов, чем ожидается;
- если размер строки b больше размера памяти, выделенного под строку a , то по указанному адресу будет записано больше байт, чем предполагалось (типичный сценарий переполнения буфера).
В отладочной версии библиотеки производится проверка значений параметров ‘a ’ и ‘b ’. Проверяются также длины строк, чтобы убедиться в их совместимости. Если обнаруживается недействительный параметр, то выдается соответствующее аварийное сообщение. В среде QNX Momentics данные сообщения об ошибках импортируются из целевой системы и выводятся на экран. В среде QNX Momentics используется также технология слежениями за случаями выделения и освобождения памяти, что дает возможность выполнять глубокий анализ использования ОЗУ.
Отладочная версия библиотеки будет работать с любым приложением, в котором используются ее функции; не нужно вносить никаких дополнительных изменений в код. Более того, разработчик может добавить библиотеку во время запуска приложения. Тогда библиотека заменит соответствующие части полной стандартной библиотеки, устраняя необходимость использовать отладочную версию полной библиотеки. В среде QNX Momentics IDE разработчик может добавить такую библиотеку при запуске программы как элемент нормального интерактивного сеанса отладки. На рис. 4 показан пример того, как в среде QNX Momentics происходит обнаружение и выдача сообщений об ошибках работы с памятью.
В отладочных версиях библиотек предоставляется проверенный "неагрессивный" метод обнаружения ошибок при вызовах библиотечных функций. Такая технология идеальна для анализа ОЗУ и для других методов анализа, которые зависят от согласованных пар вызовов, например, malloc() и free(). Другими словами, данная технология может обнаруживать ошибки на этапе исполнения только для кодов с библиотечными вызовами. При этом не обнаруживаются многие типичные ошибки, такие как встроенный код разыменования ссылки (inline pointer dereferences) или некорректные арифметические операции с указателями. Обычно при отладке осуществляется контроль только некоторого подмножества системных вызовов. Подробнее с этим можно познакомиться в статье .

Рис. 4 - Анализ ОЗУ происходит путем расстановки ловушек в области вызовов API, связанных с обращением к памяти.
Последовательность действий при динамическом анализе
Если говорить кратко, то динамический анализ включает в себя захват событий о нарушениях или других значительных событиях во встраиваемой целевой системе, импорт этой информации в среду разработки, после чего используются средства визуализации для быстрой идентификации содержащих ошибку участков кода.
Как показано на рис. 5, динамический анализ не только позволяет обнаружить ошибки, но и помогает обратить внимание разработчика на подробности расходования памяти, циклов ЦПУ, дискового пространства и других ресурсов. Процесс анализа состоит из нескольких шагов, и хороший инструмент для динамического анализа предоставляет надежную поддержку каждого шага:
- Наблюдение – прежде всего, происходит захват ошибок среды выполнения, обнаружение мест утечки памяти и отображение всех результатов в среде IDE.
- Корректировка – далее разработчик имеет возможность провести трассировку каждой ошибки назад до нарушающей работу строки исходного текста. При хорошей интеграции в среду IDE каждая ошибка будет отображаться на экране. Разработчику нужно просто щелкнуть мышью на строке ошибки, и откроется фрагмент исходного кода со строкой, нарушающей работу. Во многих случаях разработчик может быстро устранить проблему, используя доступную трассировку стека и дополнительные инструменты работы с исходным кодом в среде IDE (средства просмотра вызовов функций, средства трассировки вызовов и т.д.).
- Профилирование – устранив обнаруженные ошибки и утечки памяти, разработчик может проанализировать использование ресурсов во времени, включая пиковые ситуации, среднюю загрузку и избыточное расходование ресурсов. В идеальном случае инструмент анализа выдаст визуальное представление долговременного использования ресурсов, позволяя немедленно идентифицировать всплески в распределении памяти и иные аномалии.
- Оптимизация – используя информацию этапа профилирования, разработчик может теперь провести "тонкий" анализ использования ресурсов программой. Среди прочего, подобная оптимизация может минимизировать случаи пикового использования ресурсов и их избыточное расходование, включая работу с ОЗУ и использование времени ЦПУ.

Рис. 5 - Типовая последовательность действий при динамическом анализе
Комбинирование последовательности действий различных видов анализа в среде разработки
Каждый из инструментов статического и динамического анализа имеет свои сильные стороны. Соответственно, команды разработчиков должны использовать эти инструменты в тандеме. Например, инструменты статического анализа способны обнаруживать ошибки, которые пропускаются инструментами динамического анализа, потому что инструменты динамического анализа фиксируют ошибку лишь в случае, если во время тестирования ошибочный фрагмент кода исполняется. С другой стороны, инструменты динамического анализа обнаруживают программные ошибки конечного работающего процесса. Вряд ли нужно устраивать дискуссию по поводу ошибки, если уже обнаружено использование указателя с нулевым значением.
В идеальном случае разработчик в ежедневной работе будет использовать оба инструмента анализа. Задача существенно облегчается, если инструменты хорошо интегрированы в среду разработки на рабочем месте.
Вот какой можно предложить пример совместного использования двух видов инструментов:
- В начале рабочего дня разработчик просматривает отчет о результатах ночной компоновки. В данный отчет включаются как собственно ошибки компоновки, так и результаты статического анализа, проведенного во время компоновки.
- В отчете по статическому анализу приводятся обнаруженные дефекты наряду с информацией, которая поможет в их устранении, в том числе ссылки на исходный код. Используя среду IDE, разработчик может пометить каждую ситуацию либо как действительно найденную ошибку, либо как "ложное срабатывание". После этого производится исправление фактически присутствующих ошибок.
- Разработчик локально, внутри среды IDE, сохраняет внесенные изменения вместе с любыми новыми фрагментами кода. Разработчик не передает эти изменения обратно в систему управления исходными текстами до тех пор, пока изменения не будут проанализированы и протестированы.
- Разработчик анализирует и корректирует новый код, используя инструмент статического анализа на локальном рабочем месте. Для того чтобы быть уверенным в качественном обнаружении ошибок и отсутствии "ложных срабатываний", в анализе используется расширенная информация на уровне системы. Эта информация берется из данных выполненного в ночное время процесса компоновки/анализа.
- После анализа и "чистки" любого нового кода разработчик встраивает код в локальный тестовый образ или исполняемый файл.
- Используя инструменты динамического анализа, разработчик запускает тесты для проверки внесенных изменений.
- С помощью среды IDE разработчик может быстро выявить и исправить ошибки, о которых сообщается через инструменты динамического анализа. Код считается окончательным и готовым к использованию, когда он прошел через статический анализ, блочное тестирование и динамический анализ.
- Разработчик передает изменения в систему управления исходными текстами; после этого измененный код участвует в процессе последующей ночной компоновки.
Подобная последовательность действий похожа на применяемую в проектах среднего и большого размеров, где уже используются ночные компоновки, система управления исходными кодами и персональная ответственность за коды. Поскольку инструменты интегрированы в среду IDE, разработчики быстро выполняют статический и динамический анализ, не отклоняясь от типовой последовательности действий. В результате качество кода существенно возрастает уже на этапе создания исходных текстов.
Роль архитектуры ОСРВ
В рамках дискуссии об инструментах статического и динамического анализа упоминание об архитектуре ОСРВ может показаться неуместным. Но оказывается, что правильно построенная ОСРВ может в значительной степени облегчить обнаружение, локализацию и разрешение многих программных ошибок.
Например, в микроядерной ОСРВ типа QNX Neutrino все приложения, драйверы устройств, файловые системы и сетевые стеки располагаются за пределами ядра в отдельных адресных пространствах. В результате все они оказываются изолированными от ядра и друг от друга. Такой подход обеспечивает наивысшую степень локализации сбоев: отказ одного из компонентов не приводит к краху системы в целом. Более того, оказывается, что можно легко локализовать ошибку, связанную с ОЗУ, или иную логическую ошибку с точностью до компонента, который эту ошибку вызвал.
Например, если драйвер устройства делает попытку доступа к памяти за пределами своего контейнера процесса, то ОС может идентифицировать такой процесс, указать место ошибки и создать дамп-файл, который может быть просмотрен средствами отладки исходного кода. В то же время, остальная часть системы продолжит свою работу, а разработчик может локализовать проблему и заняться ее устранением.

Рис. 6 - В микроядерной ОС сбои в ОЗУ для драйверов, стеков протоколов и других службах не приведут к нарушению работы других процессов или ядра. Более того, ОС может мгновенно обнаружить неразрешенную попытку доступа к памяти и указать, со стороны какого кода предпринята эта попытка.
По сравнению с обычным ядром ОС микроядру свойственно необычайно малое среднее время восстановления после сбоя (Mean Time to Repair, MTTR). Рассмотрим, что происходит при сбое в работе драйвера устройства: ОС может завершить работу драйвера, восстановить используемые драйвером ресурсы и перезапустить драйвер. Обычно на это уходит несколько миллисекунд. В обычной монолитной операционной системе устройство должно быть перезагружено – этот процесс может занять от нескольких секунд до нескольких минут.
Заключительные замечания
Инструменты статического анализа могут обнаруживать программные ошибки еще до того, как код запускается на исполнение. Обнаруживаются даже те ошибки, которые оказываются не выявленными на этапах тестирования блока, системы, а также на этапе интеграции, потому что обеспечить полное покрытие кода для сложных приложений оказывается очень трудно, и это требует значительных затрат. Кроме того, команды разработчиков могут использовать инструменты статического анализа во время регулярных компоновок системы, чтобы быть уверенным в том, что проанализирован каждый участок нового кода.
Между тем, инструменты динамического анализа поддерживают этапы интеграции и тестирования, сообщая в среду разработки об ошибках (или потенциальных проблемах), возникающих при исполнении программы. Эти инструменты предоставляют также полную информацию по обратной трассировке до места возникновения ошибки. Используя эту информацию, разработчики могут выполнить "посмертную" отладку таинственного отказа программы или краха системы за значительно меньший интервал времени. При динамическом анализе через трассировку стека и переменных могут быть выявлены основополагающие причины проблемы – эта лучше, чем повсеместно использовать операторы “if (ptr != NULL)” для предотвращения и обхода аварийных ситуаций.
Использование раннего обнаружения, лучшего и полного тестового покрытия кода совместно с коррекцией ошибок помогает разработчикам создавать программное обеспечение лучшего качества и в более короткие сроки.
Библиография
- Eigler, Frank Ch., “Mudflap: Pointer Use Checking for C/C++”, Proceedings of the GCC Developers Summit 2003, pg. 57-70. http://www.linux.org.uk/~ajh/gcc/gccsummit-2003-proceedings.pdf
- “Heap Analysis: Making Memory Errors a Thing of the Past”, QNX Neutrino RTOS Programmer’s Guide. http://pegasus.ott.qnx.com/download/download/16853/neutrino_prog.pdf
О компании QNX Software Systems
QNX Software Systems является одной из дочерних компаний Harman International и ведущим глобальным поставщиком инновационных технологий для встраиваемых систем, включая связующее ПО, инструментальные средства разработки и операционные системы. ОСРВ QNX® Neutrino®, комплект разработчика QNX Momentics® и связующее ПО QNX Aviage®, основанные на модульной архитектуре, образуют самый надежный и масштабируемый программный комплекс для создания высокопроизводительных встраиваемых систем. Глобальные компании-лидеры, такие как Cisco, Daimler, General Electric, Lockheed Martin и Siemens, широко используют технологии QNX в сетевых маршрутизаторах, медицинской аппаратуре, телематических блоках автомобилей, системах безопасности и защиты, в промышленных роботах и других приложениях для ответственных и критически важных задач. Головной офис компании находится в г. Оттава (Канада), а дистрибьюторы продукции расположены в более чем 100 странах по всему миру.
О компании Klocwork
Продукты компании Klocwork предназначены для автоматизированного анализа статического кода, выявления и предотвращения дефектов программного обеспечения и проблем безопасности. Наша продукция предоставляет коллективам разработчиков инструментарий для выявления коренных причин недостатков качества и безопасности программного обеспечения, для отслеживания и предотвращения этих недостатков на протяжении всего процесса разработки. Запатентованная технология компании Klocwork была создана в 1996 г. и обеспечила высокий коэффициент окупаемости инвестиций (ROI) для более чем 80 клиентов, многие из которых входят в рейтинг крупнейших 500 компаний журнала Fortune и предлагают среды разработки программного обеспечения, пользующиеся наибольшим спросом в мире. Klocwork является частной компанией и имеет офисы в Берлингтоне, Сан Хосе, Чикаго, Далласе (США) и Оттаве (Канада).
Анализ бинарного кода, то есть кода, который выполняется непосредственно машиной, – нетривиальная задача. В большинстве случаев, если надо проанализировать бинарный код, его восстанавливают сначала посредством дизассемблирования, а потом декомпиляции в некоторое высокоуровневое представление, а дальше уже анализируют то, что получилось.
Здесь надо сказать, что код, который восстановили, по текстовому представлению имеет мало общего с тем кодом, который был изначально написан программистом и скомпилирован в исполняемый файл. Восстановить точно бинарный файл, полученный от компилируемых языков программирования типа C/C++, Fortran, нельзя, так как это алгоритмически неформализованная задача. В процессе преобразования исходного кода, который написал программист, в программу, которую выполняет машина, компилятор выполняет необратимые преобразования.
В 90-е годы прошлого века было распространено суждение о том, что компилятор как мясорубка перемалывает исходную программу, и задача восстановить ее схожа с задачей восстановления барана из сосиски.
Однако не так все плохо. В процессе получения сосиски баран утрачивает свою функциональность, тогда как бинарная программа ее сохраняет. Если бы полученная в результате сосиска могла бегать и прыгать, то задачи были бы схожие.
Итак, раз бинарная программа сохранила свою функциональность, можно говорить, что есть возможность восстановить исполняемый код в высокоуровневое представление так, чтобы функциональность бинарной программы, исходного представления которой нет, и программы, текстовое представление которой мы получили, были эквивалентными.
По определению две программы функционально эквивалентны, если на одних и тех же входных данных обе завершают или не завершают свое выполнение и, если выполнение завершается, выдают одинаковый результат.
Задача дизассемблирования обычно решается в полуавтоматическом режиме, то есть специалист делает восстановление вручную при помощи интерактивных инструментов, например, интерактивным дизассемблером IdaPro , radare или другим инструментом. Дальше также в полуавтоматическом режиме выполняется декомпиляция. В качестве инструментального средства декомпиляции в помощь специалисту используют HexRays , SmartDecompiler или другой декомпилятор, который подходит для решения данной задачи декомпиляции.
Восстановление исходного текстового представления программы из byte-кода можно сделать достаточно точным. Для интерпретируемых языков типа Java или языков семейства.NET, трансляция которых выполняется в byte-код, задача декомпиляции решается по-другому. Этот вопрос мы в данной статье не рассматриваем.
Итак, анализировать бинарные программы можно посредством декомпиляции. Обычно такой анализ выполняют, чтобы разобраться в поведении программы с целью ее замены или модификации.
Из практики работы с унаследованными программами
Некоторое программное обеспечение, написанное 40 лет назад на семействе низкоуровневых языков С и Fortran, управляет оборудованием по добыче нефти. Сбой этого оборудования может быть критичным для производства, поэтому менять ПО крайне нежелательно. Однако за давностью лет исходные коды были утрачены.Новый сотрудник отдела информационной безопасности, в обязанности которого входило понимать, как что работает, обнаружил, что программа контроля датчиков с некоторой регулярностью что-то пишет на диск, а что пишет и как эту информацию можно использовать, непонятно. Также у него возникла идея, что мониторинг работы оборудования можно вывести на один большой экран. Для этого надо было разобраться, как работает программа, что и в каком формате она пишет на диск, как эту информацию можно интерпретировать.
Для решения задачи была применена технология декомпиляции с последующим анализом восстановленного кода. Мы сначала дизассемблировали программные компоненты по одному, дальше сделали локализацию кода, который отвечал за ввод-вывод информации, и стали постепенно от этого кода выполнять восстановление, учитывая зависимости. Затем была восстановлена логика работы программы, что позволило ответить на все вопросы службы безопасности относительно анализируемого программного обеспечения.
Если требуется анализ бинарной программы с целью восстановления логики ее работы, частичного или полного восстановления логики преобразования входных данных в выходные и т.д., удобно делать это с помощью декомпилятора.
Помимо таких задач, на практике встречаются задачи анализа бинарных программ по требованиям информационной безопасности. При этом у заказчика не всегда есть понимание, что этот анализ очень трудоемкий. Казалось бы, сделай декомпиляцию и прогони получившийся код статическим анализатором. Но в результате качественного анализа практически никогда не получится.
Во-первых, найденные уязвимости надо уметь не только находить, но и объяснять. Если уязвимость была найдена в программе на языке высокого уровня, аналитик или инструментальное средство анализа кода показывают в ней, какие фрагменты кода содержат те или иные недостатки, наличие которых стало причиной появления уязвимости. Что делать, если исходного кода нет? Как показать, какой код стал причиной появления уязвимости?
Декомпилятор восстанавливает код, который «замусорен» артефактами восстановления, и делать отображение выявленной уязвимости на такой код бесполезно, все равно ничего не понятно. Более того, восстановленный код плохо структурирован и поэтому плохо поддается инструментальным средствам анализа кода. Объяснять уязвимость в терминах бинарной программы тоже сложно, ведь тот, для кого делается объяснение, должен хорошо разбираться в бинарном представлении программ.
Во-вторых, бинарный анализ по требованиям ИБ надо проводить с пониманием, что делать с получившимся результатом, так как поправить уязвимость в бинарном коде очень сложно, а исходного кода нет.
Несмотря на все особенности и сложности проведения статического анализа бинарных программ по требованиям ИБ, ситуаций, когда такой анализ выполнять нужно, много. Если исходного кода по каким-то причинам нет, а бинарная программа выполняет функционал, критичный по требованиям ИБ, ее надо проверять. Если уязвимости обнаружены, такое приложение надо оправлять на доработку, если это возможно, либо делать для него дополнительную «оболочку», которая позволит контролировать движение чувствительной информации.
Когда уязвимость спряталась в бинарном файле
Если код, который выполняет программа, имеет высокий уровень критичности, даже при наличии исходного текста программы на языке высокого уровня, полезно сделать аудит бинарного файла. Это поможет исключить особенности, которые может привнести компилятор, выполняя оптимизирующие преобразования. Так, в сентябре 2017 года широко обсуждали оптимизационное преобразование, выполненное компилятором Clang. Его результатом стал вызов функции , которая никогда не должна вызываться. #include
В результате оптимизационных преобразований компилятором будет получен вот такой ассемблерный код. Пример был скомпилирован под ОС Linux X86 c флагом -O2.
Text .globl NeverCalled .align 16, 0x90 .type NeverCalled,@function NeverCalled: # @NeverCalled retl .Lfunc_end0: .size NeverCalled, .Lfunc_end0-NeverCalled .globl main .align 16, 0x90 .type main,@function main: # @main subl $12, %esp movl $.L.str, (%esp) calll system addl $12, %esp retl .Lfunc_end1: .size main, .Lfunc_end1-main .type .L.str,@object # @.str .section .rodata.str1.1,"aMS",@progbits,1 .L.str: .asciz "rm -rf /" .size .L.str, 9
В исходном коде есть undefined behavior . Функция NeverCalled() вызывается из-за оптимизационных преобразований, которые выполняет компилятор. В процессе оптимизации он скорее всего выполняет анализ аллиасов , и в результате функция Do() получает адрес функции NeverCalled(). А так как в методе main() вызывается функция Do(), которая не определена, что и есть неопределенное стандартом поведение (undefined behavior), получается такой результат: вызывается функция EraseAll(), которая выполняет команду «rm -rf /».
Следующий пример: в результате оптимизационных преобразований компилятора мы лишились проверки указателя на NULL перед его разыменованием.
#include
Так как в строке 3 выполняется разыменование указателя, компилятор предполагает, что указатель ненулевой. Дальше строка 4 была удалена в результате выполнения оптимизации «удаление недостижимого кода» , так как сравнение считается избыточным, а после и строка 3 была удалена компилятором в результате оптимизации «удаление мертвого кода» (dead code elimination). Остается только строка 5. Ассемблерный код, полученный в результате компиляции gcc 7.3 под ОС Linux x86 с флагом -O2, приведен ниже.
Text .p2align 4,15 .globl _Z7CheckerPi .type _Z7CheckerPi, @function _Z7CheckerPi: movl 4(%esp), %eax movl $8, (%eax) ret
Приведенные выше примеры работы оптимизации компилятора – результат наличия в коде undefined behavior UB. Однако это вполне нормальный код, который большинство программистов примут за безопасный. Сегодня программисты уделяют время исключению неопределенного поведения в программе, тогда как еще 10 лет назад не обращали на это внимания. В результате унаследованный код может содержать уязвимости, связанные с наличием UB.
Большинство современных статических анализаторов исходного кода не обнаруживают ошибки, связанные с UB. Следовательно, если код выполняет критичный по требованиям информационной безопасности функционал, надо проверять и его исходники, и непосредственно тот код, который будет выполняться.